Imagine You Run a Hotel at 2am
Your AI assistant is on shift. A guest calls — they're locked out of their room. Simultaneously, a payment webhook arrives from Stripe confirming a booking. Three calendar invites need syncing. A marketing campaign is exporting 50,000 contacts to CSV. And six previous call transcripts are being analyzed by an AI to generate quality scores.
All of this happens in the same second. And none of it — not one thing — should interfere with the others.
This is the world we build for at yourang.ai. And what sits at the center of making it work isn't a database or an API — it's a message queue system precisely engineered so that urgency always wins.
yourang.ai: More Than a Hospitality AI
If you've only heard of yourang.ai as a "voice assistant for hotels," you've seen only the surface. The platform is something much larger — an AI-powered operating system for hospitality businesses, built to run the invisible layer that keeps modern properties alive.
In any given minute, yourang.ai might be:
Answering live phone calls in real time using OpenAI's voice models — in Italian, English, French, Spanish, or German
Firing an outbound call to confirm a reservation, triggered by a booking event
Processing a Stripe payment webhook and updating wallet balances across a multi-tenant organization
Syncing a confirmed appointment to a guest's Google or Apple Calendar
Evaluating the quality of the last call using AI-powered criteria scoring
Sending a WhatsApp message via Spoki to confirm a check-in time
Generating an e-invoice for a completed booking via Fattura in Cloud
Importing 10,000 new contacts from a CSV, enriching them with AI-generated summaries
Scoring a completed call against custom business criteria, then archiving the recording to S3
Running a legal identifier check (LEI) on a new organization in the background
This isn't a chatbot. This is a full-stack AI concierge infrastructure — multi-property, multi-language, multi-tenant, white-labeled for resellers across Europe. The platform is built on FastAPI + Python, Next.js, PostgreSQL, Redis, RabbitMQ, and OpenAI's Realtime API.
And behind everything visible is a background job system handling 75 distinct task types — each with radically different urgency requirements.
The Simple Version: Why You Can't Treat Everything the Same
Let's step back from the technical world for a moment. Imagine a hospital emergency room.
In an emergency room, not everyone waits in the same line. If you walk in with a broken finger, you sit down. If someone arrives with a heart attack, they go straight through. The hospital doesn't treat the broken finger as unimportant — it just knows that some things cannot wait.
Our original background job system worked like a hospital where everyone waited in the same line. A guest's OTP code — which expires in 60 seconds — sat behind a CSV export that could take 20 minutes. A payment webhook that confirms a booking waited behind a bulk email campaign. The system was "fair" in the worst possible way.
The fix wasn't to hire more staff (add more workers). If 20 doctors are all serving the same waiting room, a heart attack patient still gets stuck behind a queue of broken fingers. The fix is structural isolation: separate lanes for separate urgencies, so critical work can never be blocked by low-priority work — ever.
A flat queue is fair to tasks. A tiered queue is fair to users. We chose users.
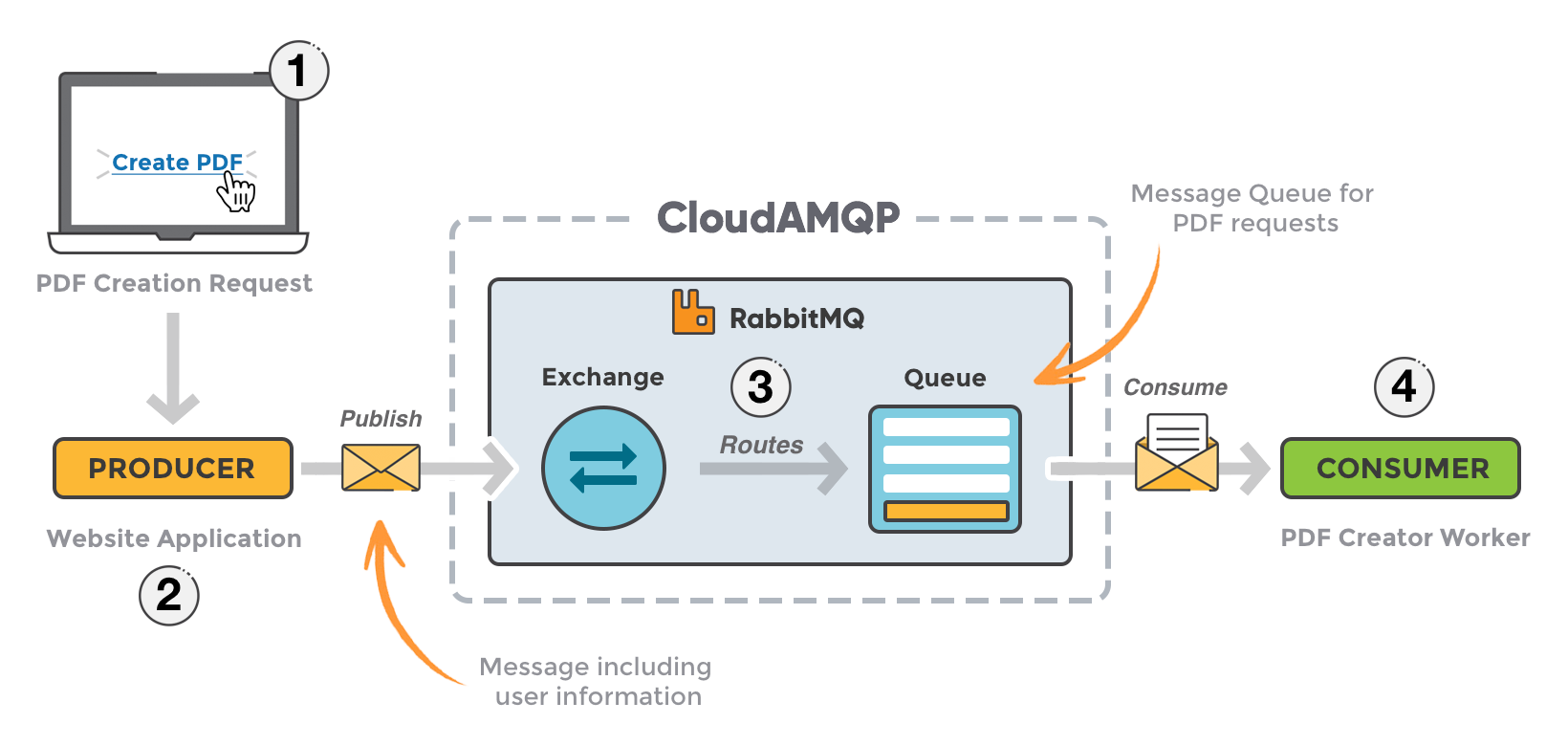
The Tool We Chose: RabbitMQ
We were already using Redis for caching and our original Celery task broker. Redis is fast, simple, and battle-tested for basic queuing. But it lacks three things we absolutely needed:
In-queue priority ordering — the ability to assign a weight to each message so that when a consumer pulls the next job, it gets the highest-priority waiting one
Dead Letter Exchanges — automatic routing of permanently-failed messages to a separate "failed jobs" queue, without any code in individual tasks
Quorum queues — Raft-replicated queues that survive broker node failures, guaranteeing no message is ever lost during restarts or crashes
RabbitMQ ships all three as first-class primitives. Redis Streams can approximate some of them, but you're building the complexity yourself. We chose RabbitMQ and let the protocol do the work.
The one crucial RabbitMQ feature that makes priority actually work — and that most people miss — is prefetch control. We'll come back to this. It's the most important 6 characters in the entire configuration.
The 6-Tier System: Giving Every Task Its Lane
After mapping every background task in the platform against a simple question — "what happens if this is delayed by 30 seconds? By 5 minutes? By 30 minutes?" — we designed six priority tiers:
Tier | Weight | SLO | The Human Translation |
|---|
CRITICAL | 10 | < 5 seconds | User is actively waiting. Failure is visible immediately. |
HIGH | 8 | < 30 seconds | User will notice a delay. Time-sensitive but not blocking. |
NORMAL | 5 | < 2 minutes | Background work. User submitted something and moved on. |
LOW | 3 | < 10 minutes | Maintenance. Nobody is watching the clock. |
BULK | 1 | Best-effort | Heavy lifting. Can run for hours. Nobody cares when. |
CALLS | Isolated | < 30 seconds | Post-call processing. Physically separated from everything else. |
CRITICAL — 7 Tasks, Zero Tolerance for Latency
These are the jobs where a user is actively blocked or where money is literally moving. There are only 7 of them — and they get priority weight 10, the highest possible:
send_otp_email_task — OTP codes expire. This fires before anything else, always.
process_stripe_webhook_task — A payment event from Stripe. The booking confirmation, the wallet update, the subscription state — all depend on this.
dial_outbound_call_task — Triggers a real phone call through our telephony provider. A human is literally waiting for the phone to ring.
send_sms_task — Time-sensitive SMS delivery for confirmations and alerts.
record_wallet_transaction_task — Financial record-keeping that must complete atomically with its trigger.
trigger_spoki_automation_task — Fires a WhatsApp automation through Spoki. Some businesses use this for instant booking confirmations.
HIGH — 20 Tasks, Time-Sensitive but Recoverable
HIGH tasks are things the user will notice if they take too long — but wouldn't call "broken". Payment confirmation emails, calendar event creation, phone number approvals, Stripe customer provisioning. Twenty tasks live here, all processed within 30 seconds.
CALLS — 9 Tasks, a Lane of Their Own
The CALLS tier is architecturally unique. It doesn't sit on the urgency spectrum — it sits outside it entirely. Every task here relates to a completed voice call: summary generation, criteria evaluation, AI quality scoring via Langfuse, recording download, usage stats, operator billing.
The reason for isolation is subtle but critical: calls come in waves. When a property has a busy check-in evening, 40 calls might complete within 30 minutes. Each triggers 6-9 post-processing tasks. Without isolation, that wave would flood the NORMAL queue and delay invoices, RAG indexing, and campaign syncs for hours. With isolation, the calls worker handles its own domain completely independently — and even within that queue, tasks have their own priority order (recording download runs before cosmetic summaries).
The 4-Worker Architecture: How the Lanes Are Staffed
Six tiers map to four dedicated Docker containers. This is the physical reality of the system:
RabbitMQ Broker — 6 queues, 6 DLQs
│
├── critical + high ──────→ celery-worker-urgent
│ concurrency=8, prefetch=1
│ "The ER team — always ready, never preloaded"
│
├── normal ────────────────→ celery-worker-normal
│ concurrency=4, prefetch=4
│ "The standard operations team"
│
├── low + bulk ────────────→ celery-worker-deferred
│ concurrency=4, prefetch=4
│ "The overnight crew — thorough, unhurried"
│
└── calls ─────────────────→ celery-worker-calls
concurrency=4, prefetch=1
"The call center — isolated, focused"
RedBeat Scheduler (Redis-backed)
└── Publishes periodic tasks into the correct tier queue
The celery-worker-urgent container handles both CRITICAL and HIGH. The reason: both SLOs are short (under 5s and 30s), and they share a physical hardware pool. RabbitMQ serves messages from the critical queue first due to higher priority weight — so a CRITICAL message is always delivered before a waiting HIGH message. The urgent worker has 8 concurrent processes dedicated to nothing but time-sensitive work.
The Secret Weapon: prefetch=1
Here's the detail that makes or breaks priority queuing, and that most tutorials skip entirely.
When Celery workers connect to RabbitMQ, they can pre-fetch multiple messages — pulling them out of the broker and into a local buffer. This improves throughput. But it also means those pre-fetched messages are invisible to the priority system. Once a worker has pulled 4 messages into its local buffer, a newly-arrived CRITICAL message sits in the broker queue, unable to jump the buffered messages.
prefetch=4 means priority is respected when messages are first pulled. prefetch=1 means priority is respected on every single delivery — one at a time.
On the celery-worker-urgent and celery-worker-calls containers, we set prefetch=1. This means each of the 8 worker processes holds exactly one un-acknowledged message at a time. The moment it finishes, it reaches back to RabbitMQ and asks for the next one. RabbitMQ then delivers the highest-priority available message at that instant.
This is true priority preemption. If 50 HIGH tasks are waiting and one CRITICAL arrives, the very next process to free up gets the CRITICAL — every single time. Not a best-effort guarantee. Not "probably." Guaranteed by the protocol.
The Routing Brain: TASK_TIER_MAP
Every task in the system has exactly one home — declared in a single Python dictionary called TASK_TIER_MAP. This is the canonical source of truth for the entire queue system. No routing rules are buried in config files or inferred by convention. Every task name maps explicitly to its tier:
# back/app/core/queue_routing.py
TASK_TIER_MAP: dict[str, QueueTier] = {
# CRITICAL — fires before everything else
"app.tasks.email.send_otp_email_task": QueueTier.CRITICAL,
"app.tasks.payment_webhook_handler.process_stripe_webhook_task": QueueTier.CRITICAL,
"app.tasks.telnyx.dial_outbound_call_task": QueueTier.CRITICAL,
"app.tasks.sms.send_sms_task": QueueTier.CRITICAL,
# HIGH — 30s SLO
"app.tasks.google_calendar.create_event_in_google_calendar_task": QueueTier.HIGH,
"app.tasks.stripe_tasks.create_stripe_customer_for_organization": QueueTier.HIGH,
"app.tasks.email.send_payment_success_email_task": QueueTier.HIGH,
# NORMAL — 2min SLO
"app.tasks.rag_tasks.process_document_task": QueueTier.NORMAL,
"app.tasks.fattura_in_cloud_tasks.create_fic_invoice_task": QueueTier.NORMAL,
# LOW — 10min SLO
"app.tasks.contact_summary.generate_contact_summary_task": QueueTier.LOW,
# BULK — best effort
"app.tasks.contact_import.process_large_contact_import": QueueTier.BULK,
"app.tasks.contact_export.export_contacts_task": QueueTier.BULK,
# CALLS — isolated
"app.tasks.call_summary.generate_call_summary_task": QueueTier.CALLS,
"app.tasks.call_langfuse_scoring.score_call_langfuse_task": QueueTier.CALLS,
# ... 61 more tasks
}
When a service dispatches a task — my_task.delay(...) — Celery consults task_routes, which is built from this map. The task is published to the exact queue with the exact priority weight of its tier. No inference. No wildcards. No surprises.
A sentinel unit test — test_no_task_is_missing_from_tier_map — runs on every CI push and loads every registered task from all 4 live workers, then asserts that each one exists in TASK_TIER_MAP. Any task added without a tier entry fails the build before it ever reaches staging.
Publisher Confirms: No "Fire and Forget" Illusions
Every .delay() call uses publisher confirms. This is a RabbitMQ AMQP feature where the broker sends an acknowledgement back to the publisher — not just "I received the bytes," but "I have durably stored this message." This eliminates an entire class of lost-job bugs: tasks that appear dispatched but were dropped during a transient network blip or broker restart.
The Safety Net: Dead Letter Queues
What happens when a task fails? It retries — with exponential backoff and jitter, up to 3 times (more for critical external APIs). But what if it fails all 3 times? What if the Stripe API is genuinely down? What if a third-party calendar provider returns a server error for 10 minutes straight?
Without a safety net, those tasks disappear. Silently. No trace, no recovery.
With our system, they land in a Dead Letter Queue. Every main queue has a corresponding DLQ — six queues means six DLQs. When a task exhausts its retry budget, a Celery signal fires _handle_permanent_task_failure(), which routes the message to the appropriate DLQ via RabbitMQ's Dead Letter Exchange. The entry is also written to Redis, making it queryable through our admin API.
Queue topology — 12 total
critical ←→ critical.dlq
high ←→ high.dlq
normal ←→ normal.dlq
low ←→ low.dlq
bulk ←→ bulk.dlq
calls ←→ calls.dlq
DLQ messages expire after 30 days.
Operators can inspect via GET /admin/dlq/by-tier
Operators can redrive via POST /admin/dlq/{task_id}/redrive
Critically: no individual task writes DLQ logic. The signal is global. Individual task authors focus on their domain logic and retry parameters — the failure handling is a platform concern, not a per-task concern.
The Scheduler: Time-Based Work Without Thundering Herds
Not all work is triggered by user actions. A large portion runs on a schedule — health checks every minute, calendar channel renewals daily, stale subscription cleanup nightly, invoice retries hourly.
We use RedBeat — a Redis-backed Celery beat scheduler — for this. The twist: even though our task broker is RabbitMQ, the scheduler state lives in Redis. RedBeat stores the schedule, tracks last-run times, and publishes tasks into the correct RabbitMQ tier queue on schedule.
# back/app/core/celery.py
celery_app.conf.beat_schedule = {
"celery-beat-health-check": {
"task": "app.tasks.health_check.celery_beat_health_check_task",
"schedule": crontab(minute="*/5"),
"options": {"expires": 180}, # Skip if worker is 3min behind
},
"renew-google-calendar-channels": {
"task": "app.tasks.google_calendar_sync.renew_watch_channels_task",
"schedule": crontab(hour="3", minute="0"),
"options": {"expires": 3600}, # Skip if worker is 1hr behind
},
"cleanup-stale-subscriptions": {
"task": "app.tasks.remove_pending_subscriptions_without_payments.cleanup_pending_subscriptions_task",
"schedule": crontab(hour="2", minute="0"),
"options": {"expires": 3600},
},
# ... more scheduled tasks
}
The expires option is mandatory on every scheduled task. Without it, if celery-beat goes offline for several hours and then restarts, it queues every missed execution simultaneously — a "thundering herd" that floods workers. With expires, stale executions are discarded and only the current one runs.
The Complete Picture: How It All Connects
┌─────────────────────────────────────────────────────────────────────┐
│ yourang.ai Platform │
│ │
│ FastAPI Application │
│ ├── HTTP request arrives (booking, call event, payment webhook) │
│ ├── Service layer processes the request │
│ └── task.delay() → TASK_TIER_MAP → correct queue + priority weight │
└──────────────────────────┬──────────────────────────────────────────┘
│ AMQP + Publisher Confirm
▼
┌─────────────────────────────────────────────────────────────────────┐
│ RabbitMQ Broker │
│ │
│ ┌──────────┐ ┌──────┐ ┌────────┐ ┌─────┐ ┌──────┐ ┌───────┐ │
│ │ critical │ │ high │ │ normal │ │ low │ │ bulk │ │ calls │ │
│ │ prio=10 │ │ p=8 │ │ p=5 │ │ p=3 │ │ p=1 │ │ iso │ │
│ └────┬─────┘ └──┬───┘ └───┬────┘ └──┬──┘ └──┬───┘ └───┬───┘ │
│ │ │ │ │ │ │ │
│ Each queue has a Dead Letter Exchange binding to its .dlq │
└───────┼───────────┼──────────┼───────────┼─────────┼───────────┼───┘
│ │ │ │ │ │
└─────┬─────┘ │ └────┬────┘ │
▼ ▼ ▼ ▼
┌──────────────┐ ┌────────────┐ ┌────────────┐ ┌──────────────┐
│celery-worker │ │celery-work │ │celery-work │ │celery-worker │
│ -urgent │ │ -normal │ │ -deferred │ │ -calls │
│concurrency=8 │ │concurr.=4 │ │concurr.=4 │ │concurrency=4 │
│ prefetch=1 │ │ prefetch=4 │ │ prefetch=4 │ │ prefetch=1 │
└──────────────┘ └────────────┘ └────────────┘ └──────────────┘
RedBeat Scheduler (Redis) → publishes scheduled tasks into queues above
Queue Types: A Deliberate Tradeoff
Not all 6 queues are the same type. This is one of the most nuanced architectural decisions:
Queue | Type | Why |
|---|
critical, high, calls | Classic (x-max-priority) | Needs in-queue priority ordering. Quorum queues don't support x-max-priority. |
normal, low, bulk | Quorum | Raft-replicated across nodes. Survives broker failure. No priority needed — FIFO is correct. |
All *.dlq | Classic | Needs persistence (30-day TTL). No priority sorting needed. |
The tension: x-max-priority only works on classic queues. Quorum queues — which replicate across a RabbitMQ cluster using Raft consensus — don't support per-message priority. So for CRITICAL and HIGH queues, we made a deliberate tradeoff: priority ordering over multi-node replication. For NORMAL, LOW, and BULK, where ordering doesn't matter, we get the full durability guarantee of quorum replication.
75 Tasks, 6 Tiers: The Full Distribution
At the time of writing, the platform runs 75 registered background tasks across all tiers:
Tier | Tasks | Worker | Sample Work |
|---|
CRITICAL | 7 | celery-worker-urgent | OTP, Stripe webhook, outbound call, SMS, wallet transaction |
HIGH | 20 | celery-worker-urgent | Payment emails, calendar events, Stripe customer, phone approval |
NORMAL | 16 | celery-worker-normal | RAG indexing, invoices, calendar sync, campaign reconciliation |
LOW | 12 | celery-worker-deferred | Contact summaries, subscription cleanup, LEI verification |
BULK | 11 | celery-worker-deferred | Contact import/export, bulk email, catalogue PDF, S3 cleanup |
CALLS | 9 | celery-worker-calls | Call summary, criteria eval, Langfuse scoring, recording download |
Every task follows the same implementation pattern: a synchronous Celery decorator wrapping an async function, with mandatory fields for name, retry behavior, jitter, backoff, and time limits. The synchronous wrapper exists because Celery workers are synchronous processes — the async logic runs inside run_async_in_celery(), a thin bridge to an event loop.
@celery_app.task(
bind=True,
name="app.tasks.call_summary.generate_call_summary_task",
autoretry_for=(Exception,),
retry_backoff=True,
retry_jitter=True,
retry_backoff_max=600,
max_retries=3,
soft_time_limit=300,
time_limit=360,
)
def generate_call_summary_task(self: Any, call_id: str, organization_id: str) -> None:
run_async_in_celery(_generate_call_summary_async(call_id, organization_id))
async def _generate_call_summary_async(call_id: str, organization_id: str) -> None:
async with get_async_session() as db:
call = await get_call_by_id_selector(db, call_id, organization_id)
if not call:
return
summary = await openai_client.generate_summary(call.transcript)
await update_call_summary_selector(db, call_id, organization_id, summary=summary)
What This Architecture Makes Possible
Before this system, everything was a gamble. A wave of contact imports could delay an OTP email. A surge of post-call processing could slow down payment confirmations. Every spike in one domain bled into every other.
After this system, the guarantees are structural:
An OTP email always fires in under 5 seconds, regardless of queue depth in any other tier
A hotel call completes and its 9 post-processing tasks begin immediately in their own isolated lane — the next incoming call is unaffected
50,000 contacts can be imported overnight in BULK while the morning shift triggers CRITICAL payment webhooks without a microsecond of contention
A failed Stripe webhook doesn't disappear — it lands in critical.dlq, is inspectable by operators, and can be redriven into any tier with a single API call
A RabbitMQ restart doesn't lose a single message — publisher confirms held the producer until the message was durably committed
If RabbitMQ itself has issues, a single environment variable — CELERY_BROKER_KIND=redis — switches the entire system back to Redis in seconds, with zero code changes
What We're Building Next
The architecture is solid, but we're not done evolving it. Here's what's on the near-term roadmap:
RabbitMQ clustering — Expanding from single-node to a 3-node Raft cluster so even CRITICAL and HIGH queues get full quorum durability, not just FIFO queues.
Prometheus + Grafana dashboards — Real-time per-tier queue depth alerts, consumer saturation warnings, DLQ growth rate tracking, and SLO breach detection.
Dynamic priority overrides — Operator-level controls to temporarily elevate a specific task type (e.g., prioritize all calendar tasks during a high-demand week) via feature flag, without a code deploy.
AI-assisted DLQ triage — An automated tool that reads failed tasks in DLQs, classifies root causes (provider outage, data error, timeout), and recommends redrive vs. discard — reducing operator toil on failure recovery.
Rate limiting per tier — Capping throughput on BULK tasks to prevent downstream service saturation (email provider rate limits, SMS gateway caps) even within the isolated BULK worker.
The Principle Behind All of It
Every architectural decision in this system comes back to one thing: urgency must be a first-class property, not an afterthought. Not something you bolt on later. Not something you hope "just works" with enough horizontal scaling.
When someone calls a hotel at 2am and the AI picks up, there are dozens of jobs happening simultaneously in the background — some of them critical, some of them trivial. The guest doesn't see any of that. They just experience a platform that feels instant.
That feeling of speed and reliability isn't luck. It's architecture.
If you're building a platform where background work spans wildly different urgency levels, I'd love to hear how you're solving it. The combination of RabbitMQ's message primitives, Celery's task model, and deliberate prefetch discipline is what made this possible for us — and the patterns translate to any domain where "fair" queueing hurts the users who matter most.