Sometimes the most dangerous production bugs do not look like infrastructure problems. They look like business logic.
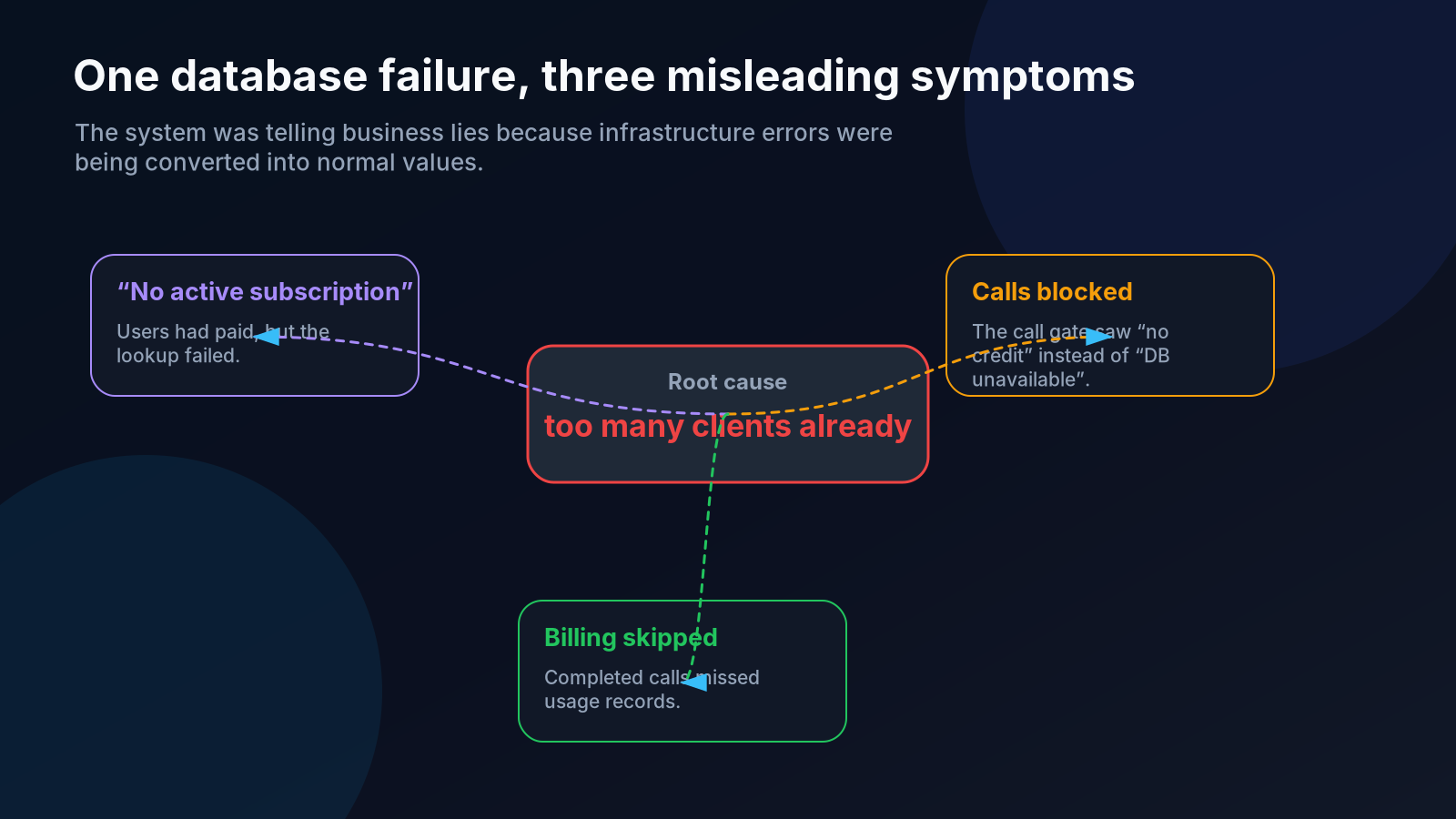
That is exactly what happened here. Users of an AI voice-assistant platform were suddenly being told they had no active subscription. Support checked the accounts. The subscriptions were active. Payments were correct. The database rows existed.
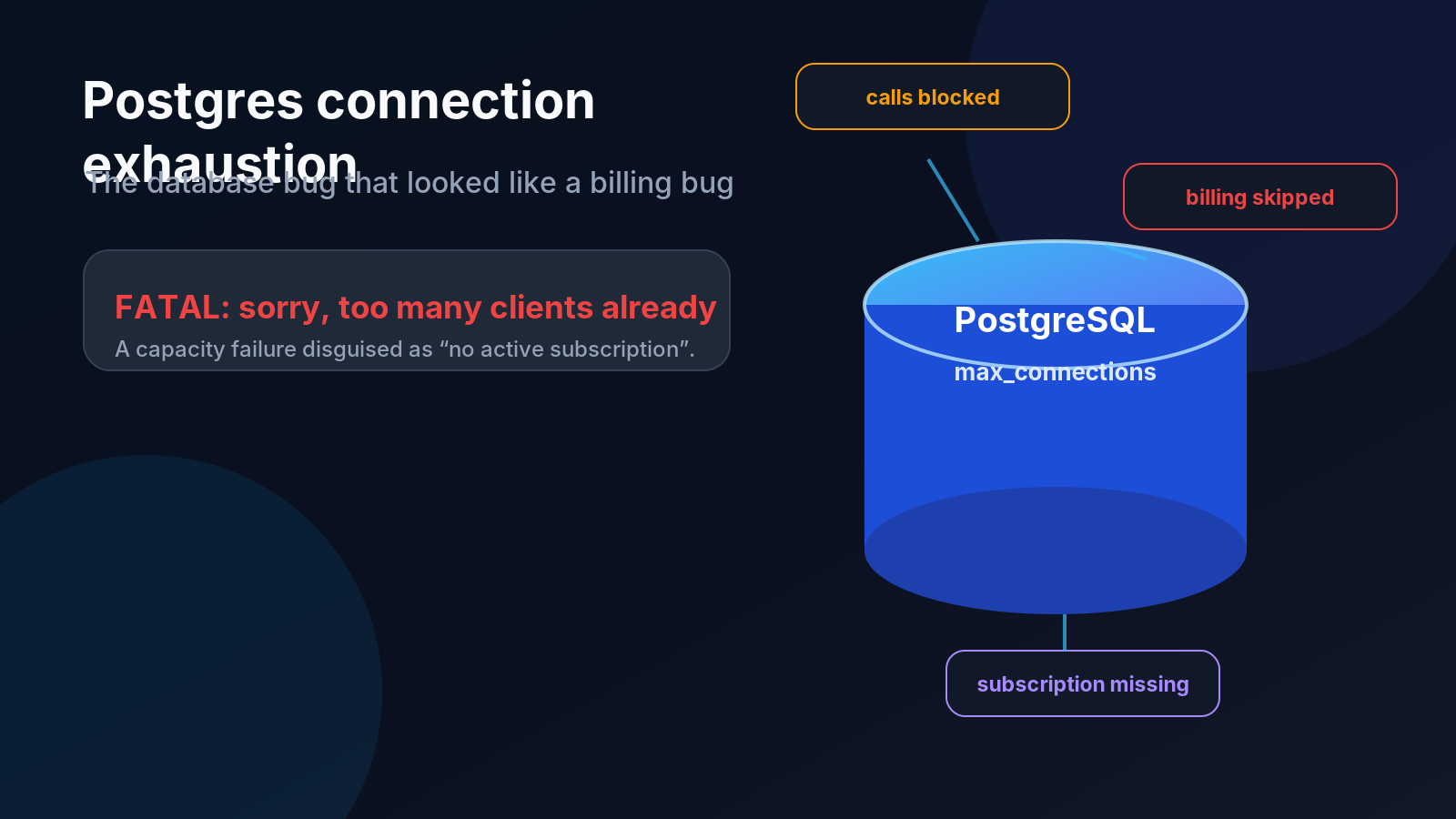
At the same time, two other symptoms appeared in different parts of the system:
Three symptoms. Three support threads. Three parts of the codebase.
But the real error was one line from PostgreSQL:
FATAL: sorry, too many clients already
PostgreSQL had exhausted its max_connections limit. A pure infrastructure failure had been translated into a confident, incorrect business answer: “this customer has no subscription.”
That translation was the real bug.
One failure, three misleading symptoms
The platform was built around a few critical moving parts:
FastAPI for the async backend.
SQLAlchemy 2.x using the asyncpg driver.
Celery prefork workers for background jobs.
PostgreSQL as the database.
Multi-tenant architecture, where each reseller tenant has a physically separate database and therefore its own SQLAlchemy engine and connection pool.
The critical path was post-call billing. When an AI phone call ended, a Celery task processed usage and billing. If that task failed silently, money was lost. If subscription checks failed incorrectly, real customers were blocked.
The system did not fail because one big thing went wrong.
It failed because three smaller mistakes lined up perfectly:
A database error was swallowed and returned as None.
Celery workers created and destroyed event loops in a way that orphaned async database connections.
Connection pool sizing ignored the real multiplication of workers × tenants × pools.
Let’s walk through each one.
Act I: The most expensive return None
The first bug lived in a helper that fetched the active subscription for an organization.
The code looked harmless:
async def get_active_subscription(db, organization_id):
try:
result = await db.execute(
select(PlanSubscription).where(...)
)
return result.scalar_one_or_none()
except Exception:
logger.warning("Failed to fetch subscription")
return None
That final line is the crime scene.
In normal business logic, None meant: this organization has no active subscription.
But during connection exhaustion, db.execute() could not get a database connection. asyncpg raised an exception. The broad except Exception handler caught it, logged a warning, and returned None anyway.
So now None meant two completely different things:
The subscription does not exist.
The system failed to check whether the subscription exists.
Those are not similar outcomes. They require opposite responses.
A real missing subscription should block access. A temporary database failure should retry, return 503 Service Unavailable, or delay billing until the database recovers.
But the callers could not know the difference. They saw None and acted accordingly: block the call, skip the billing, or tell the user to upgrade.
The infrastructure failure had been laundered into a business decision.
Never let the same return value mean both “the answer is no” and “I failed to get the answer.”
Act II: The real error finally appears
Once the team stopped trusting the surface symptom, the trail led to Sentry and PostgreSQL logs showing the real issue:
OperationalError: (asyncpg.exceptions.TooManyConnectionsError)
FATAL: sorry, too many clients already
That raised the obvious question: why were there so many connections?
The application had connection pools. The configured pool sizes looked modest. On paper, the database should not have been anywhere near the limit.
But pg_stat_activity showed many more connections than expected. A lot of them were idle, old, and tied to Celery worker processes.
That was the clue: the pool was not simply too large. Connections were being leaked.
Act III: The event loop leak
The leak came from the bridge between synchronous Celery tasks and async application code.
Celery prefork tasks are synchronous functions. The app code was async. So every task used a helper like this:
def run_async_in_celery(coro):
loop = asyncio.new_event_loop()
asyncio.set_event_loop(loop)
try:
return loop.run_until_complete(coro)
finally:
loop.close()
asyncio.set_event_loop(None)
At first glance, this looks clean. Create a loop, run the coroutine, close the loop.
But with SQLAlchemy async pools, it is the wrong lifecycle.
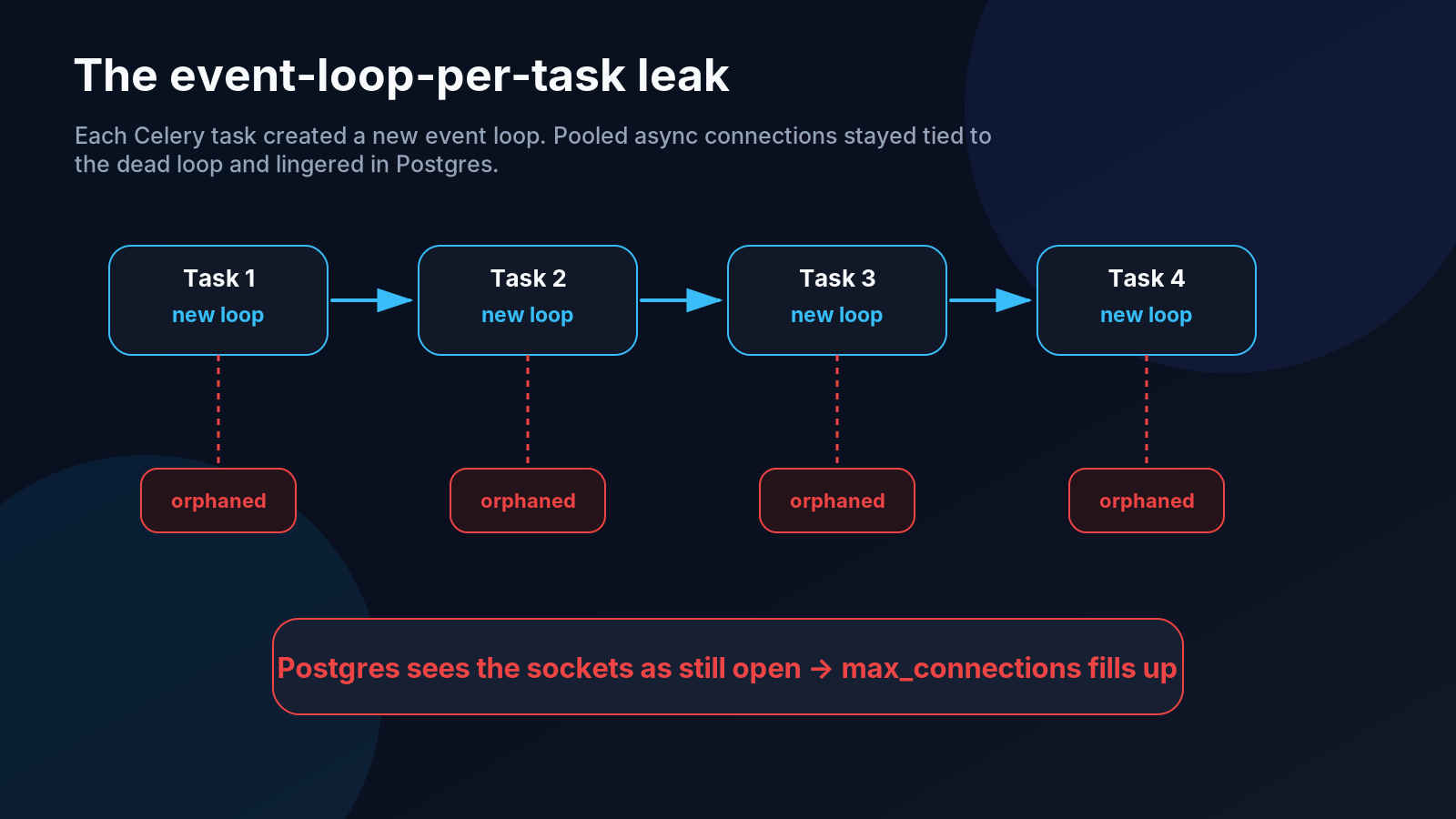
Async database connections are tied to the event loop that created them. If every task creates a new loop, opens pooled connections, finishes, and then closes the loop, the pool cannot safely reuse those connections on the next task. The Python side loses the useful lifecycle, but PostgreSQL may still see the sockets as open.
The result: orphaned connections.
Now multiply that by busy Celery workers:
Task 1 creates a loop and opens connections.
Task 1 finishes and closes the loop.
Some connections remain visible to PostgreSQL.
Task 2 creates a new loop and opens more connections.
Repeat hundreds or thousands of times.
The worker becomes a connection factory.
The fix: one persistent loop per worker process
The better pattern for Celery prefork is a single event loop per worker process.
A Celery prefork child process runs one task at a time, so one persistent loop is safe. More importantly, connections stay tied to a live loop, and the pool can actually reuse them.
_worker_loop: asyncio.AbstractEventLoop | None = None
def _get_worker_loop() -> asyncio.AbstractEventLoop:
global _worker_loop
if _worker_loop is None or _worker_loop.is_closed():
_worker_loop = asyncio.new_event_loop()
asyncio.set_event_loop(_worker_loop)
return _worker_loop
def run_async_in_celery(coro):
try:
asyncio.get_running_loop()
except RuntimeError:
# Normal Celery prefork case: no loop is already running.
return _get_worker_loop().run_until_complete(coro)
# Defensive fallback: if a loop is already running, isolate the coroutine
# in another thread instead of nesting event loops.
with concurrent.futures.ThreadPoolExecutor(max_workers=1) as executor:
return executor.submit(_run_in_isolated_loop, coro).result()
This change turned Celery from “new loop per task” into “one reusable loop per process.”
That stopped the orphaned connection buildup.
Act IV: The connection math was still wrong

Fixing the leak was necessary, but it was not enough.
The architecture was multi-tenant. Each tenant had its own database, and each database had its own SQLAlchemy engine and connection pool. Each worker process could create its own engines.
That means the real connection math was not simply:
pool_size = 5
It was:
worker processes
× tenant engines touched by each worker
× (pool_size + max_overflow)
= theoretical maximum connections
That number can explode quietly.
A setup that looks safe per pool can be unsafe globally. If the system only touches some tenants some of the time, the problem may stay hidden for months. But “it usually works” is not the same thing as capacity planning.
The fix had three parts.
1. Bound every pool
Every SQLAlchemy engine — API, worker, platform database, tenant database — needed explicit pool settings.
That included:
pool_size
max_overflow
pool_timeout
pool_recycle
The important part was centralization. Pool configuration moved into shared helpers so future engines could not accidentally be created with unsafe defaults.
2. Cap worker usage
Celery worker process counts were sized so that the theoretical maximum stayed under PostgreSQL’s connection limit by construction.
The question became:
If every worker hits every relevant tenant at once, are we still safe?
If the answer is no, the system is not actually safe.
3. Prepare PgBouncer, but roll it out dark
The long-term structural answer was PgBouncer in transaction pooling mode.
But PgBouncer changes application behavior. For example, transaction pooling is not friendly to session state, and prepared statement caching needs care with asyncpg. So the PgBouncer work was prepared behind flags and shipped dark.
Nothing routed through it immediately.
That mattered. The team separated the code fix from the infrastructure migration, so each change could be tested, enabled, and rolled back independently.
Act V: Make the code tell the truth

The most important fix was not just reducing connection usage.
It was changing what the application said when the database failed.
The team introduced a shared classifier for transient database errors:
def is_transient_db_error(exc: Exception) -> bool:
if isinstance(exc, (OperationalError, InterfaceError, DisconnectionError)):
return True
markers = (
"too many clients",
"connection was closed",
"timed out",
"connection refused",
)
text = str(exc).lower()
return any(marker in text for marker in markers)
Then the subscription selector changed from “catch everything and return None” to “re-raise infrastructure errors.”
except Exception as exc:
if is_transient_db_error(exc):
raise
logger.warning("Failed to fetch subscription", exc_info=exc)
return None
Now None could mean what callers always thought it meant: no active subscription.
But there was one more twist.
The re-raised errors were being caught again higher up by other broad except Exception handlers in service and task layers.
So the same guard had to be added throughout the call chain:
except Exception as exc:
if is_transient_db_error(exc):
raise
handle_as_business_error(exc)
That is the uncomfortable lesson: swallowing errors is not usually one bug. It is an ecosystem.
When you fix propagation at the source, you also have to walk the whole path from raise-site to boundary and prove that nothing swallows the error again.
At the top of the stack, transient database errors got proper destinations:
That changed the system’s behavior from misleading to honest.
A database outage now looked like a database outage.
How the fix was verified
The team did not stop at “the code looks right.” They verified the fix in multiple ways.
Unit tests for the paths that failed
The new tests checked that transient database errors re-raised through:
subscription selectors,
service layers,
usage-processing tasks,
API exception handlers.
The important point: the tests covered the exact failure mode, not just the happy path.
Pooling-mode testing
The backend was tested with normal SQLAlchemy pooling and with DB_USE_NULL_POOL=true, preparing the application for a PgBouncer rollout.
Production graph watching
After the loop fix, worker connection counts stopped climbing. pg_stat_activity stopped accumulating old idle connections from Celery workers.
That was the operational proof.
The five lessons
1. The real bug is often where exceptions are caught
The surface symptom was “no subscription.” The real problem was “PostgreSQL refused a connection.”
When a symptom makes no sense, search for broad exception handlers between the symptom and the dependency.
2. Never let None mean two things
“Not found” and “could not check” must be different outcomes.
Use exceptions, result types, explicit status objects — anything except the same value.
3. Async resources have lifetimes
If you run async code from synchronous workers, be careful with event loops.
The pattern “create loop → run coroutine → close loop” can break resource lifecycles when pooled async connections are involved.
4. Do the connection math globally
Per-pool limits are not enough in multi-process, multi-tenant systems.
Always calculate:
processes × engines × (pool_size + max_overflow)
Then compare it to PostgreSQL’s real max_connections.
5. Error propagation fixes need adversarial review
The first fix can be technically correct and still useless if another layer catches the error again.
After changing error handling, trace the full path from the database driver to the final API response or worker retry.
A 10-minute audit for your own codebase
Run these searches today:
# 1. Swallow-and-return-None candidates
grep -rn "except Exception" --include="*.py" -A 3 | grep -B 2 "return None"
# 2. Event-loop-per-call patterns in sync → async bridges
grep -rn "new_event_loop" --include="*.py" -A 8 | grep "loop.close()"
# 3. Engines created without explicit pool bounds
grep -rn "create_async_engine\|create_engine" --include="*.py" \
| grep -v "pool_recycle\|pool_timeout\|NullPool"
Then answer three questions:
If PostgreSQL refused connections for 30 seconds, what would users see?
What is your theoretical maximum connection count?
Do money-touching background tasks retry transient database failures, or do they silently skip work?
If you cannot answer confidently, you probably have a version of this bug waiting for traffic.
Final thought
This incident was not caused by one dramatic failure.
It came from a quiet return None, an event loop lifecycle that looked cleaner than it was, and connection math that only made sense on paper.
The most expensive bugs are often like that. They do not crash loudly. They disguise themselves as normal business outcomes.
And that is why infrastructure errors should never be allowed to lie.
Image note: the visuals in this article are custom SVG/PNG diagrams created to explain the incident flow, connection leak, pool multiplication, and final error-handling path.