
Claude Code Models and Effort Levels: Explained Simply
Model selection and effort level solve different problems. The model controls Claude’s underlying capability; the effort level controls how much work Claude does before responding.
8 min read

On May 28, 2026, Anthropic released Claude Opus 4.8 — a direct upgrade to Opus 4.7 that ships at the same price. It isn't a flashy reinvention; it's a sharpening release focused on reliability, honesty, and how you actually run the model in real workflows. Here's a crisp, clear rundown of everything new.
The standout improvement in Opus 4.8 is honesty. AI models often jump to conclusions, confidently claiming progress when the evidence is thin. Anthropic trained Opus 4.8 to flag its own uncertainty and avoid unsupported claims. The result: it is roughly four times less likely than Opus 4.7 to let flaws in code it has written pass unremarked. In short — it tells you when it's unsure and catches its own bugs instead of declaring victory early.
Anthropic's alignment team also reported that Opus 4.8 reaches new highs on prosocial traits like supporting user autonomy, with rates of misaligned behavior substantially lower than Opus 4.7 — now comparable to its best-aligned model, Claude Mythos Preview.
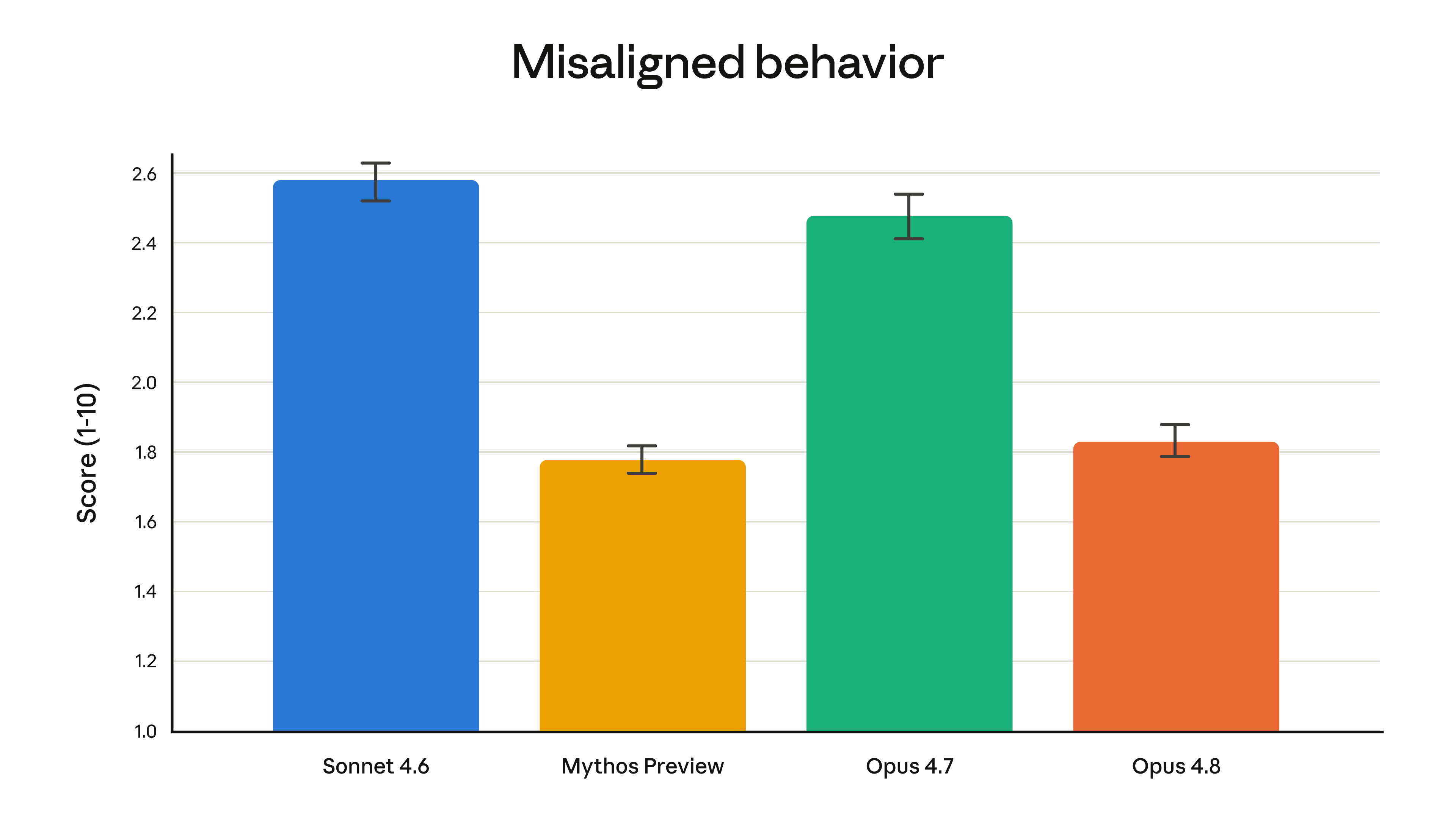
The gains are real but modest — this is a refinement, not a leap. The most meaningful improvements show up in agentic and coding tasks.
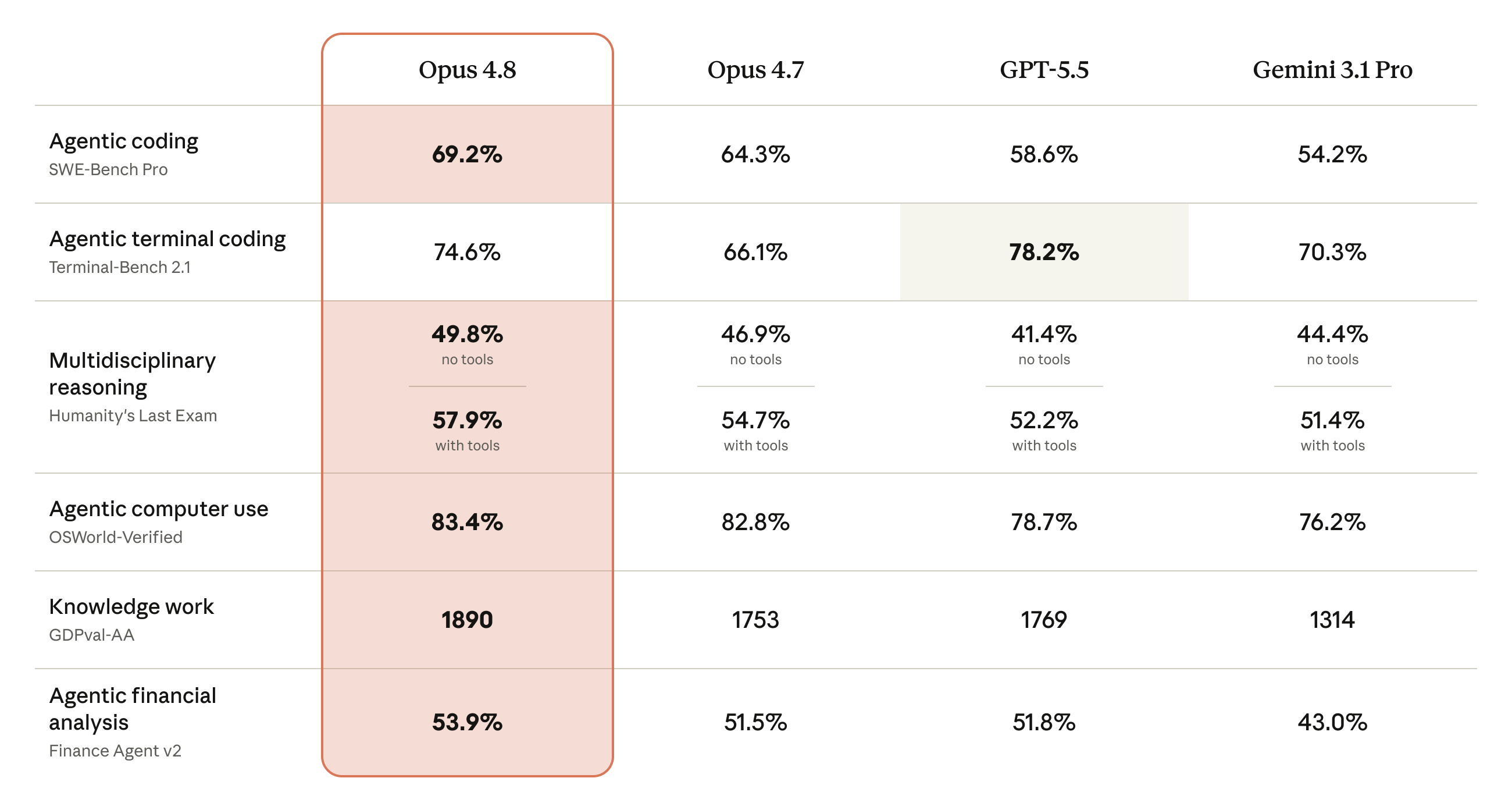
Benchmark | Opus 4.7 | Opus 4.8 |
|---|---|---|
SWE-bench Verified (coding) | 87.6% | 88.6% |
SWE-Bench Pro | 64.3% | 69.2% |
OSWorld-Verified (computer use) | 82.3% | 83.4% |
Terminal-Bench 2.1 | — | 74.6% |
GPQA Diamond (reasoning) | — | 93.6% |
Online-Mind2Web (browser agent) | lower | 84% |
GDPval-AA (knowledge work) | — | 1890 Elo |
Available in research preview, this lets Claude plan a task, then dispatch hundreds of parallel subagents in a single session. The subagents tackle the problem from independent angles, refute each other's findings, and iterate until answers converge — then Claude verifies outputs before reporting back. With Opus 4.8, agents run longer, enabling codebase-scale migrations across hundreds of thousands of lines of code from kickoff to merge, using the existing test suite as the bar. Available on Claude Code Enterprise, Team, and Max plans.
A new control next to the model selector lets you choose how much effort Claude puts into a response. Higher effort means deeper, more frequent thinking for better answers; lower effort means faster responses that use your rate limits more slowly. Available on all plans.
Fast mode runs at roughly 2.5× the speed of the standard Opus 4.8 endpoint and is now three times cheaper than fast mode on previous Claude models. Toggle it with /fast inside Claude Code.
The Messages API now accepts system entries inside the messages array. Developers can update Claude's instructions mid-task — permissions, token budgets, or environment context — without breaking the prompt cache or routing through a user turn. A meaningful quality-of-life win for agent builders.
Opus 4.8 defaults to high effort (down from Opus 4.7's xhigh default). On coding tasks this spends a similar number of tokens as 4.7's default — but scores higher. Power users can dial up to "extra" (xhigh) or "max" for difficult tasks and long-running async workflows.
Standard: $5 per million input tokens / $25 per million output tokens — unchanged from Opus 4.7
Fast mode: $10 per million input / $50 per million output
Model ID: claude-opus-4-8 on the Claude API
No price increase for a frontier model is unusual — and arguably the single biggest reason to upgrade today.
Databricks: Opus 4.8 unlocks "a step change in agentic reasoning" in its Genie agent, reasoning over PDFs and diagrams at 61% cheaper token cost than Opus 4.7.
Cognition (Devin): fixed the comment-verbosity and tool-calling issues seen in 4.7.
Cursor: more efficient tool calling — fewer steps for the same intelligence.
Hebbia: better citation precision and token efficiency on dense financial filings.
Anthropic is working on lower-cost models with Opus-level capabilities, and plans to release a new, more intelligent class of model. As part of Project Glasswing, a small number of organizations are currently using Claude Mythos Preview for cybersecurity work — and Anthropic expects to bring Mythos-class models to all customers in the coming weeks once stronger cyber safeguards are in place.
Claude Opus 4.8 is a modest but tangible upgrade. The benchmark bumps are incremental, but the real story is operational: sharper judgment, dramatically better honesty, parallel-subagent workflows, mid-task system messages, a cheaper fast mode — all at the same price. For anyone doing serious agentic or coding work, it's an easy upgrade.
Was this helpful?
Give it a zap to let me know.
Or share it with someone
Model selection and effort level solve different problems. The model controls Claude’s underlying capability; the effort level controls how much work Claude does before responding.

Claude Fable 5 and Claude Mythos 5 were temporarily suspended after the US government applied export controls on June 12, requiring Anthropic to restrict access to foreign nationals. Because Anthropic says it had no reliable way to verify nationality in real time, it suspended both models for all users. Those controls were lifted on June 30, and Fable 5 was restored globally starting July 1 across Claude Platform, Claude.ai, Claude Code, and Claude Cowork.
Claude Sub-Agents — The npm for AI developers! (sub-agents CLI)